7 Ways to Build More Solid Betting Strategies

Protecting against over simplified data mining and overfitting is essential to ensure that your filters and forecasting strategies are robust and generalise well for applying to new data in the future.
Overfitting: In mathematical modeling, overfitting is “the production of an analysis that corresponds too closely or exactly to a particular set of data, and may therefore fail to fit to additional data or predict future observations reliably”. Wikipedia
Overfitting with Betaminic strategies happens when we play with filters and find a profitable historical trend that is not actually a true trend, but merely the result of luck and bending filters to cut out losing bets.
Here are some solid methods you can use to mitigate this problem:
1. **Proper data partitioning**:
Divide your historical data into training and test sets. Use the training set to develop and tune your filters and models, and use the test set to evaluate their performance. This will help you get a more realistic estimate of future performance and prevent the model from memorizing the training data.
For example, if we have data over 11 seasons from 2012 to 2023, then we could divide that into 8 seasons of training data and 3 seasons of test data. In this way you could research your system based on the 8 seasons of training data to “train the model”, and the see if the filters you found work on new data by applying them to the 3 test seasons. The 8 + 3 season separation is just an example and you should try any separation that you feel is meaningful depending on the data you have available. You could also consider using the latest data to train the model and testing that on older data. Or using alternate seasons or months as the training data and then the other half of the seasons as the test data. There are many ways to apply this method.
In Tom Whitaker’s book “Big Data Betting on Football – The Betaminic Guide 2” (which can be downloaded free here) he divided 8 years of data into 6 years of training data and 2 years of test data to create a number of strategies.

In a number of publicly shared Betaminic strategies, users include what data separation method they used in the description section to remember how they researched the strategy. They sometimes call the training data the “Research Period” (RP) and the test data the “Test Period” (TP).
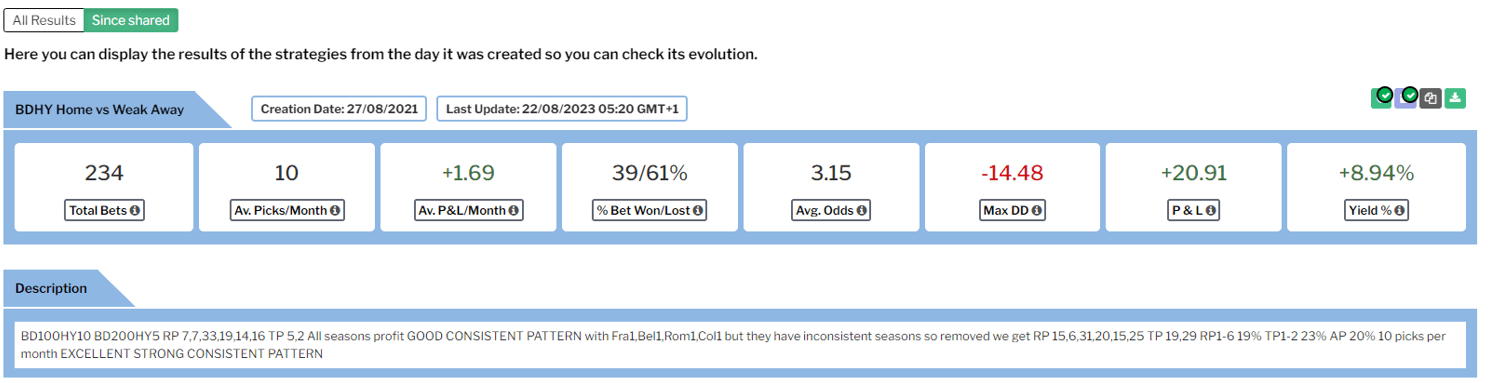
In the image below the user writes “RP 7,7,33,19,14,16 TP 5,22” in the description section of the BDHY Home vs Weak Away strategy to suggest that they use 6 seasons for the training data and the yield they found in each of those seasons, and they used 2 seasons for the test data and the yield they found in those 2 seasons. In this way you can see how the trend found in the training data continued in the test data.

The Since Shared data of the same strategy shows that even after being shared, the trend has continued with 8.94% ROI from 234 bets.
2. **Cross-validation**:
Instead of a single split between training and test data, consider using cross-validation techniques, such as k-fold cross-validation. This involves splitting the data into multiple training/test sets and averaging the results to obtain a more robust assessment of model performance.
For example, if you have a standard research methodology of how you add filters, then you can apply that method to the same data set but using different training and test sets to see if similar models get produced.
For instance, if your usually style is to first apply objective filters such as recent form or team names, then apply subjective filters such as odds filters, then to filter leagues out based on positive or negative inclusion. Then this three step process could be applied to one data set but with different validation setups.
A) The first 7 seasons as training seasons and the newest 4 as test seasons
B) The last 7 seasons as training seasons and the oldest 4 as test seasons
C) Alternate 1,3,5,7,9,11 seasons as training seasons and the 2,4,6,8,10 as test seasons
D) Alternate months as training seasons and the other months as test seasons.
If you end up with vastly different results from the same filter application method, then it can change the way you view your research method. You can also then try applying a different method, such as leaving the subjective filtering to after the league filtering, and then see if similar or different results come up.
When you apply several different research methods and use cross-validation, then you can look at the different filters you have researched and choose a medium ground that best covers the value trend found, or even just focus on the core filters that worked across all the tests.
3. **Keep a separate validation data sample**:
Set aside a validation data sample that is not used in the model fitting process. This sample will be used only for a final performance evaluation prior to implementing the strategy in a real betting environment.
This is splitting the data into 3 parts. A training set, a test set and a validation set.
In the case of training and test sets, then we may be tempted to go back after a bad test result and then change the training set filters and try again. Also, if we are doing cross-validation, we end up seeing the results of few of the test sets, which can color our next attempts, and through our diligent research we end up contaminating the test data to an extent and biassing our subsequent research efforts. For this reason, having a final, separate set of data that has not had the model applied to it at any stage, can by useful as a final validation of the model.
The tricky balance here is judging the size of each data sets for our training set, test set and validation set. Making one set too small can reduce its meaning, but the training set will benefit from as much data as possible to avoid overfitting. This is up to the researcher to judge.
4. **Limit the number of variables and combinations**:
Avoid using a large number of variables or testing too many filter combinations. The more you test, the greater the risk of finding apparent patterns by chance alone.
The more filters that get applied, the smaller the data set becomes. The smaller the data set is, the more chance that its results were just due to luck. So for this reason, it is better to use fewer filters.
Also, we should not play with filters to “find” a winning pattern. This has a high chance of filtering out losing bets and ending up with just winning bets that appear to be a trend but are in fact just the result of deleting losing results. This leads on to the next point.
5. **Focus on solid fundamentals**:
Rather than relying solely on datamining, base your filters and models on solid fundamentals and football knowledge. This could include factors such as team performance at home and away, the status of key players, coach’s tactics, historical clashes between teams, among others.
By fundamentals we mean objectively measurable factors. This includes the form of a team, goals scored, goals conceded and games played this season which can be found in the Betaminic database. But also team news such as if the main striker is injured or the captain suspended or a new manager taking charge of his first game, which require a quick check before placing the actual bet. The odds of a match can be considered more subjective since they are decided by humans, either the opening odds and the closing odds after the public market forces have pushed them up or down. The solid fundamentals need to be considered, and having built a model from the Betaminic database, either through the Betamin Builder or through Betlamp, then adding a little human insight on top of that big data can improve the ROI of a system greatly. If a star striker is injured, it might be worth skipping that bet. Statistics do not negate the need for football knowledge. Statistics give us powerful tools so that we know which matches to look at and analyse for our final decision. It can be hard not to bet on a pick that you have already paid for, but sometimes the ability to know when not to bet is as important as knowing when to bet.
6. **Test with out-of-sample data**:
If possible, obtain additional data outside the original sample to test the effectiveness of your filters and models on completely new data before implementing them on real bets.
One way to do this is to “paper” test the strategy by keeping a log in a spreadsheet of imaginary bets.
If you have formulated a strategy with Betlamp, then you need to keep a log of your possible bets to see if the strategy works before placing real money bets on them.
If you have researched a strategy with the Betamin Builder, then you can save that strategy or share it to the public strategies page and keep an eye on it for a number of bets without paying any money for picks on it just yet. The Betamin Builder logs the Since Created / Since Shared results and you can see if the trend continues beyond the training, test and validation data into brand new data.
7. **Periodic re-evaluation**:
Conduct a periodic re-evaluation of your filters and strategies. Sports markets can change over time, and what worked in the past may not be effective in the future. Keep your models up to date and adapt your approaches as necessary.
On the Betamin Builder share strategies page you can often see “(Updated xxxx-xx-xx)” in some of the strategy names that show where a user has gone back and re-researched their strategy including the latest data. The number of leagues available in the Betaminic database has grown and every year there are over 30,000s of new matches data to be added to strategies.

Make statistics work for you
Remember that no model or filter can guarantee absolute success in sports betting, as there is always an element of uncertainty. How ever, by following sound validation practices and guarding against over-fitting and overly simplistic datamining, you can increase the likelihood of more consistent and realistic results in the future.
Sign Up for free to access the Betamin Builder here.
25 Most Profitable Teams to bet on in 2023
Learn how to automate Betaminic strategies with a betting bot.
Access Betlamp, the amazing free statistics tool here.
Read more Betaminic posts here.